NTSS_ICR_SupportingStatementB_03-12-2025
NTSS_ICR_SupportingStatementB_03-12-2025.docx
National Traffic Safety Survey
OMB: 2127-0772
National Traffic Safety Survey
ICR Part B
Information Collection Request Supporting Statement: Section B
National Traffic Safety Survey
OMB Control No. 2127-New
Abstract:1
The National Highway Traffic Safety Administration (NHTSA) of the U.S. Department of Transportation is seeking approval of this information collection request (ICR) to allow NHTSA to conduct six information collections as part of a new voluntary research effort titled the National Traffic Safety Survey (NTSS). The purpose of the surveys is to obtain up-to-date information about road user attitudes and behaviors related to motor vehicle safety. The respondents will be members of the public that are contacted through nationally representative sampling methods. Participation by respondents will be voluntary. Each of the surveys will contain a set of core questions that will be asked across all surveys and a combination of two additional sections consisting of questions related to seat belts, distracted driving, new vehicle technologies, or traffic safety and traffic safety enforcement. This collection only asks respondents to report their answers; there are no record-keeping costs to respondents. Each survey will have a combination of two of the four topic areas, and the order of the topic areas will be varied. The NTSS is intended to collect approximately 6,001 surveys, or 1,000 of each type of survey (with 500 surveys collected for each order in which the additional topic sections would appear). NHTSA intends to conduct a pilot of the survey first with approximately 250 respondents, followed by a full administration of the survey to 6,001 respondents, and a possible follow-up administration of the survey two years later with 6,001 respondents. For purposes of this ICR, NHTSA assumes that the survey will be conducted twice, as well as the pilot being conducted once. Accordingly, the estimates for the three-year approval are based on an average annual burden based on these targets, with an estimate that there will be approximately 681 annual respondents for each of the six information collections.
The contractor conducting this information collection is ICF International, Inc. ICF’s IRB will review and approve this data collection prior to fielding. ICF’s IRB meets all federal requirements in 45 CFR 46, is registered with the Office for Human Research Protections, and has a Federalwide Assurance (FWA00002349).
NHTSA will use the information from this collection to produce a technical report that presents the results of the survey, as well as a dataset that does not contain any personally identifiable information (PII). The technical report will provide aggregate (summary) statistics and tables as well as the results of statistical analyses of the information, but it will not include any PII. The technical report will be shared with State highway safety offices, local governments, policymakers, researchers, educators, advocates, and others who may wish to use the data from this survey to support their work. NHTSA estimates the total annual burden associated with this ICR to be 2,046 hours and $0.
B.1. Describe the potential respondent universe and any sampling or other respondent selection method to be used.
The NTSS will collect critical population-level data that will help NHTSA understand the attitudes, knowledge, and behaviors related to traffic safety issues of road users and gauge the safety needs of the nation. For each full administration of the survey, NHTSA aims to collect information from approximately 6,001 adults (18 years and older) in the United States. The proposed study will employ statistical sampling methods to collect information from the target population and draw inferences from the sample to the target population. The technical report and dataset will be shared with State highway safety offices, local governments policymakers, researchers, educators, advocates, and others who may wish to use the data from this survey to support their safety work.
B.1.a. Respondent Universe
The respondent universe is adults ages 18 years and older, residing in the 50 States and the District of Columbia. Based on the 2020 Census, there were 258.3 million adults in the U.S. in 2020.2 Thus, the size of the target population is approximately 258 million people.
B.1.b. Respondent Sampling
The NTSS will be conducted as a web and mail multi-mode survey, with households randomly selected from an address-based sampling frame (ABS). The sampling frame will be based on address data from the U.S. Postal Service (USPS) computerized Delivery Sequence File (DSF) of residential addresses. The DSF is derived from mailing addresses maintained and updated by USPS and available from commercial vendors.3,4 With 150-million residential addresses nationally, the DSF provides a comprehensive frame that will reach nearly the entire population of people who live at addresses that receive mail delivery. (Note, however, that group quarters, such as dormitories and assisted living facilities, are not identified within the DSF, and group quarters are under-covered by the DSF.)
The NTSS will use a stratified two-stage cluster sample, where households are the primary sampling unit, and a single adult (age 18+) within a household is the secondary sampling unit. Stratification will be based on the 10 NHTSA regions.5 NHTSA regions were selected as strata for two reasons. First, prior NHTSA national surveys have found differences in self-reported traffic safety behaviors across the regions. For example, the 2016 Motor Vehicle Occupant Protection (MVOSS) survey found that seat belt use ranged from 86% to 96% across the 10 NHTSA regions,6 and the 2011 National Survey of Speeding Attitudes and Behaviors found that NHTSA region was a significant predictor of the percentage of drivers classified as “speeders” within each region.7 Second, NHTSA regions were selected as strata because doing so ensures sufficient representation in the sample to allow NHTSA Regional Offices and Regional stakeholders to examine the data associated with their regions.
Households invited to participate in the pilot study will be excluded from being invited to participate in the first survey administration. However, households invited to participate in the first survey administration will not be excluded from being invited to participate in the second survey administration, if the second administration is conducted approximately two years later. The chance that the same household would be selected to receive an invitation to complete the first and second survey administrations is low, as is the chance that the same respondent within a household would be selected to respond to the first and second survey administrations.
B.1.b.1 Sampling Frame
The sampling frame will be based on address data from the USPS computerized DSF of residential addresses. The DSF is a computerized file that contains all delivery point addresses serviced by the USPS with the exception of general delivery. Each delivery point is a separate record that conforms to all USPS-addressing standards. The initial studies of the DSF estimated that it provided coverage of approximately 97-98% of the household population.8,9 The DSF coverage in rural areas tends to be lower than in urban areas10 but is increasing as more rural areas are converted to city-style addresses for 911 services.11 Nonetheless, the DSF address frame provides a near complete sampling frame for household population surveys in the United States. With over 150-million residential addresses nationally, the DSF provides a comprehensive frame that will reach nearly the entire population of people living at addresses that receive mail delivery.
The DSF cannot be obtained directly from the USPS. It must be purchased through a licensing agreement with private vendors. These vendors are responsible for updating the address listing from the USPS and augmenting the addresses with information (e.g., name, telephone number) from other data sources. ICF International, Inc., the contractor that will implement the NTSS for NHTSA, will obtain the DSF augmented sample from Marketing Systems Group (MSG). By geocoding an address to a Census block, the MSG file augments the DSF by merging Census and other auxiliary information from the Census data files and other external data sources. MSG appends household, geographic, and demographic data to the frame.
MSG maintains a monthly updated, internal installation of the DSF from the Postal Service. By applying a series of enhancements to the DSF, MSG evolves this database of mail delivery into a sampling frame capable of accommodating multiple layers of stratification or clustering when selecting probability-based samples. Address enhancements provided by MSG include amelioration of some of the known coverage problems associated with the DSF, particularly in rural areas where more households rely on P.O. Boxes and inconsistent address formats.
There were approximately 150 million residential addresses in the DSF as of November 2022. This estimate excludes business addresses. It also excludes addresses labeled as “No Stat” which are generally addresses where there is no mail delivery, such as buildings for which building permits have been obtained but mail delivery has not commenced.
The sampling frame for the NTSS will include all residential addresses in the DSF, including city-style addresses (89.3% of residential addresses in the DSF), P.O. boxes (10.7%), rural routes (< 0.1%), and highway contracts (< 0.1%). The frame will exclude P.O. boxes where the household also receives home delivery. The DSF classifies P.O. Boxes as Only Way to Get Mail (OWGM) (1.4 million) or traditional Post Office Box where the household also receives delivery at a street address (14.3 million). The NTSS will only include the OWGM P.O. Boxes since people having traditional Post Office Boxes are represented in the sampling frame based on their home delivery address.
The DSF includes flags identifying the address as seasonal (< 0.1%) or vacant (8.0%). However, the “vacant” flag can be miscoded, or the unit can change status between the time that the sample is selected, and the survey is administered. In two recent ABS surveys conducted by the contractor for this study, while about 50% of surveys mailed to addresses marked “vacant” in the DSF were returned as undeliverable, the remaining 50% were likely delivered and yielded response rates comparable to addresses not marked “vacant.” Yet, as mailings to vacant addresses reach respondents less efficiently and at a higher cost, the contractor will stratify the addresses as “flagged vacant” or “not flagged.” Then, they will proportionally allocate 50% less sample to the vacant stratum. By contrast, excluding addresses flagged as “vacant” altogether would increase the efficiency of data collection but would have a small impact on coverage of U.S. households. Thus, to maximize coverage of the population, the NTSS frame will include these addresses.
Drop points are single delivery points or receptacles that service multiple businesses/families; examples include a single mailbox shared by more than one business/family, a boarding or fraternity house, or a gated community where mail for all homes is delivered to a gatehouse. Drop units—individual delivery units within drop points—represent less than 1% of all residential addresses. In actual mail delivery, the drop units have names attached so that mail can be appropriately routed within the building by tenant or landlord. However, the commercial DSF file only provides the number of drop units within a drop point address. The most common approaches to handling drop points in address-based samples are to either exclude the drop points (or those with more than a few drop units) or include all drop units for any selected drop point since there is no basis for selection within the drop unit. NTSS will include drop points in the sampling frame. The drop points will be expanded based on the number of units at that location. If a drop point is selected, research on the units will be conducted to determine the way that units are specified within that drop point.
Some addresses are classified as educational (< 0.1%), which represents student housing. They are effectively a special type of drop point since there are not individual unit addresses within the buildings. They will be included in the sample, like drop points, particularly given the underrepresentation in most population surveys of the young adult sample.12
In total, the frame for NTSS includes 136 million mailable addresses. We estimate that this frame covers the approximately 126 million households, and 258 million adults, within the U.S. Table 1 below describes the stratification for the NTSS, considering both the 10 NHTSA Regions and the “flagged vacant” versus “not flagged” strata.
Table 1. Frame Counts and Expected Sample Size by NHTSA Region and Vacant Status.
NHTSA Region |
ABS Frame |
NTSS Sample |
|||
Total Addresses |
Flagged Vacant |
Total |
Flagged Vacant |
Not Flagged |
|
United States |
136,358,101 |
8% |
28,700 |
1,202 |
27,498 |
Region 1 (Maine, Massachusetts, New Hampshire, Rhode Island, Vermont) |
4,776,820 |
10% |
1005 |
53 |
952 |
Region 2 (Connecticut, New Jersey, New York, Pennsylvania) |
18,323,536 |
8% |
3,857 |
160 |
3,697 |
Region 3 (Delaware, District of Columbia, Kentucky, Maryland, N. Carolina, Virginia, West Virginia) |
14,244,046 |
9% |
2,998 |
148 |
2,850 |
Region 4 (Alabama, Florida, Georgia, S. Carolina, Tennessee) |
21,829,778 |
8% |
4,595 |
185 |
4,410 |
Region 5 (Illinois, Indiana, Michigan, Minnesota, Ohio, Wisconsin) |
22,733,244 |
8% |
4,785 |
198 |
4,587 |
Region 6 (Louisiana, New Mexico, Mississippi, Oklahoma, Texas) |
17,633,823 |
9% |
3,711 |
175 |
3,536 |
Region 7 (Arkansas, Iowa, Kansas, Missouri, Nebraska) |
7,446,158 |
11% |
1,567 |
90 |
1,477 |
Region 8 (Colorado, Nevada, North Dakota, South Dakota, Utah, Wyoming) |
5,673,570 |
7% |
1,194 |
46 |
1,148 |
Region 9 (Arizona, California, Hawaii) |
17,474,947 |
5% |
3,678 |
103 |
3,575 |
Region 10 (Alaska, Idaho, Montana, Oregon, Washington) |
6,222,179 |
6% |
1,310 |
44 |
1,266 |
As required in the task order under which this survey will be conducted, the target number of respondents is 6,001 nationally for the first administration and 6,001 nationally for the optional second administration (approximately two years later). For the task order, this target sample size was selected based both on the number of completed surveys obtained in the 2016 Motor Vehicle Occupant Safety Survey (MVOSS), as well as the desire for the total survey sample size to be large enough to permit estimates for subgroup analyses (e.g., age, sex, etc.) We expect the design effect for the NTSS to be similar to the design effect for the 2016 MVOSS, which was 1.73 and 1.76 for the two versions of the survey.13 Thus, assuming a 1.75 design effect due to weighting, we expect national estimates to have a margin of error of +/–1.7 percentage points at the 95% confidence level and error margins. Additionally, under these assumptions, a subgroup that represents at least 10% of the total survey sample will have a margin of error of +/- 5.3 percentage points at the 95% confidence level and error margins. Please see Section B.2.c (“Precision of Sample Estimates”) for more information on how these margins of error were calculated.
The task order under which this survey will be conducted also required that 1,200 invitations be sent as part of the pilot study. Assuming a response rate of 21% (based on recent similar surveys), this number of invitations is expected to yield a sample size of 250 (therefore for the pilot study. Please see Section B.1.c (“Response Rate”) for more information on how the pilot study’s sample size was estimated.
The NTSS frame will be stratified into the 10 NHTSA regions14 and the overall sample of 28,700 mailings (per survey administration) will be allocated proportionately based on the total number of residential addresses in each region. The survey questionnaire will consist of core questions and four survey modules that cover questions on behaviors, experiences, attitudes, and beliefs related to: seat belts, distracted driving, new vehicle technologies, and traffic safety and traffic safety enforcement. Each respondent will complete the set of core questions and two of the four modules, and the order of presentation of the two modules will be counterbalanced across participants. Considering that each respondent will complete the core questions and two topic modules, and that the order of each topic module will vary (first or second), the total number of permutations of survey contents is 12 [P(4,2) = 4!/(4-2)! = 12] (Table 2). Given the target sample size of 6,001, the target number of completed surveys in each permutation is approximately 500 (with one permutation having one additional estimated completes, to equal 6,001). With each topic module appearing six times across permutations, the target sample size per module is approximately 3,000, as displayed in Table 2.
Table 2. Permutation Sample Size and Module Assignment.
|
Permutation |
|||||||||||
Survey Contents |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
Core questions |
X |
X |
X |
X |
X |
X |
X |
X |
X |
X |
X |
X |
Topic module #1 |
SB |
SB |
SB |
DD |
NT |
TS |
DD |
DD |
NT |
TS |
NT |
TS |
Topic module #2 |
DD |
NT |
TS |
SB |
SB |
SB |
NT |
TS |
DD |
DD |
TS |
NT |
Target completes |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
500 |
Note: SB = seat belts. DD = distracted driving. NT = new technologies. TS = traffic safety and enforcement. |
||||||||||||
Addresses from the DSF are drawn based on a 1-in-k systematic sample so that each address has an equal probability of selection within each stratum. The ABS database is sorted by ZIP+4 within State to ensure a geographically proportional allocation.
B.1.b.3 Within-Household Selection
A number of respondent selection methods have been tested for ABS mail surveys, including for the Behavioral Risk Factor Surveillance System (BRFSS).15 Although past studies have indicated a tendency for the wrong person to complete the survey when applying birthday methods of within-household selection,16 a recent evaluation of birthday selection methods for ABS surveys found a small degree of self-selection in larger households; however, the impact on the substantive estimates was small.17 Considering this finding and the simplicity of implementing the birthday methods, the adult within the household who has the next birthday will be selected to complete the survey (as opposed to the last birthday or a split next/last sample). The within-household selection instructions will be included in all contacts with the household.
B.1.c. Response Rate
Table 2 details our assumptions for sample size and return rate by data collection wave. These assumptions are based on similar contact waves and return rates achieved for the 2022 National Survey of Speeding Attitudes and Behaviors (NSSAB, OMB Control No. 2127-0613) and the 2023 National Survey of Pedestrian and Bicyclist Attitudes, Knowledge, and Behaviors (NSPBAKB, OMB Control No. 2127-0684), two national surveys about traffic safety behaviors and attitudes similar in methodology to the NTSS.
The 2023 NSPBAKB achieved a response rate of 21%. We anticipate the NTSS will also achieve this response rate based on using an incentive of $10 contingent on completing the survey, as did the NSPBAKB. Also similar to NSPBAKB, the NTSS will also include a $1 pre-incentive.
Assuming a response rate of 21%, we expect to draw an initial sample of 28,700 addresses (Table 3). We also assume that 5% of these records (1,435) will be returned as non-deliverable after the first two mailings. We expect the 27,265 remaining valid records—following the five-contact protocol—will result in an estimated 6,001 returned surveys for a return rate of 21%. In Table 3, response rates for each contact wave, as well as the distribution of completed web vs. mail surveys at each wave, have been estimated from the results of the 2023 NSPBAKB. After adjusting for ineligible addresses, we expect a response rate of 22% based on the American Association of Public Opinion Research (AAPOR) response rate formula #1 (RR1).
Table 3. Expected Data Collection Quantities and Response Rates for Survey Administration 1.
Contact
|
Number of Mailings
|
Expected Return Rate1
|
Completed Surveys2 |
||
Total |
Web |
||||
Contact 1 (Initial Invitation) |
28,700 |
8% |
2,296 |
2,296 |
n/a |
Contact 2 (Reminder Postcard #1) |
28,700 |
3% |
861 |
861 |
n/a |
Non-deliverable |
(-1,435) |
|
|
|
|
Contact 3 (1st Paper Survey Mailing) |
24,108 |
5% |
1,205 |
482 |
723 |
Contact 4 (Reminder Postcard 2) |
24,108 |
3% |
723 |
253 |
470 |
Contact 5 (2nd Paper Survey Mailing |
22,903 |
4% |
916 |
293 |
623 |
Total |
|
21%2 |
6,001 |
4,185 |
1,816 |
1 Expected return rates, both overall and for each contact wave, are based on results from the 2023 National Survey of Bicycle and Pedestrian Attitudes and Behaviors (NSPBAKB, OMB Control No. 2127-0684). 2 Note that these numbers have been rounded to the nearest whole number. |
|||||
For the pilot study, we also assume a response rate of 21% and will select an initial sample of 1,200 addresses as required in the task order (Table 3). We also assume that 5% of these records (60) will be returned as non-deliverable after the first two mailings. We expect the 1,140 remaining valid records—following the five-contact protocol—will result in an estimated 250 returned surveys for a return rate of 21%. In Table 4, response rates for each contact wave, as well as the distribution of completed web vs. mail surveys at each wave, have been estimated from the results of the 2023 NSPBAKB. After adjusting for ineligible addresses, we expect a response rate of 22% based on the American Association of Public Opinion Research (AAPOR) response rate formula #1 (RR1).
Table 4. Expected Data Collection Quantities and Response Rates for Pilot Survey.
Contact
|
Number of Mailings
|
Expected Return Rate1
|
Completed Surveys2 |
||
Total |
Web |
||||
Contact 1 (Initial Invitation) |
1,200 |
8% |
96 |
96 |
n/a |
Contact 2 (Reminder Postcard #1) |
1,200 |
3% |
36 |
36 |
n/a |
Non-deliverable |
(-60) |
|
|
|
|
Contact 3 (1st Paper Survey Mailing) |
1,008 |
5% |
50 |
20 |
30 |
Contact 4 (Reminder Postcard 2) |
1,008 |
3% |
30 |
11 |
19 |
Contact 5 (2nd Paper Survey Mailing |
958 |
4% |
38 |
12 |
26 |
Total |
|
21%2 |
250 |
175 |
75 |
1 Expected return rates, both overall and for each contact wave, are based on results from the 2023 National Survey of Pedestrian and Bicyclist Attitudes, Knowledge, and Behaviors (NSPBAKB, OMB Control No. 2127-0684). 2 Note that these numbers have been rounded to the nearest whole number. |
|||||
B.2. Describe the procedures for the collection of information.
B.2.a Data Collection Protocol
The contractor, ICF, will select a national, stratified random sample of households from the DSF, as described in the previous section. Each household will be mailed an initial letter requesting participation in the survey. The survey will employ the next birthday method for random selection of one respondent aged 18 or over from the household.
Web response is NHTSA’s preferred method for the survey. Therefore, the survey will initially offer only a web response mode, where the letter requests the selected household member to go to a designated website to take the survey. Each letter/address will contain a unique Master ID that will be used to access the website and will help track whether someone from a household completed the survey. For those that do not respond, there will be a series of additional contact waves that will add alternative modes of responding. The contact waves are presented in Table 5. Households that respond or refuse the survey will be removed from subsequent contacts.
Table 5. NTSS Contact Protocol.
Contact |
Description |
Contents |
Schedule |
Contact 1 (Initial Invitation) |
Mailed invitation letter offering web response |
Cover letter with unique web survey login, QR code, instructions, $1 pre-incentive |
Day 1 |
Contact 2 (Reminder Postcard #1) |
Mailed reminder postcard |
Postcard with unique web survey login, QR code, instructions |
Day 14 |
Contact 3 (1st Paper Survey Mailing) |
Mailed package offering web or mail response |
Cover letter with unique web survey login, QR code, printed questionnaire, prepaid return envelope, instructions |
Day 35 |
Contact 4 (Reminder Postcard #2) |
Mailed reminder postcard |
Postcard with unique web survey login and paper survey reminder, QR code, instructions |
Day 56 |
Contact 5 (2nd Paper Survey Mailing) |
Mailed replacement package offering web or mail response |
Cover letter with unique web survey login, QR code, printed questionnaire, prepaid return envelope, instructions |
Day 77 |
Close data collection |
|||
B.2.b Spanish-Language Data Collection
Materials will be sent in both English and Spanish to households highly likely to speak Spanish. These bilingual materials will be sent to households in Census block groups where the percentage of limited English-speaking households18 is at least 15% of the total households in the block group. We estimate that these block groups represent over 50% of the Spanish language isolate population. Areas outside these block groups will receive an English-language letter that contains information at the bottom, in Spanish, on how to access and complete the survey in Spanish. This approach is designed to balance the high cost of sending bilingual materials with ensuring those most likely to be Spanish Speaking with limited English proficiency can participate. The web survey will have the option to complete the survey in English or Spanish.
B.2.c Precision of Sample Estimates
The objective of the sampling procedures described above is to produce a random sample of the target population. This means that with a randomly drawn sample, one can make inferences about population characteristics within certain specified limits of certainty and sampling variability.
The margin of error, d, of the sample estimate of a population proportion, P, equals:
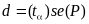
Where tα equals 1.96 for 1-α = 0.95, and the standard error of P equals:
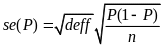
Where:
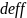 =
design effect arising from the combined impact of the random
selection of one eligible individual from a sample household, and
unequal weights from other aspects of the sample design and weighting
methodology, and
=
design effect arising from the combined impact of the random
selection of one eligible individual from a sample household, and
unequal weights from other aspects of the sample design and weighting
methodology, and
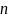 =
the size of the sample (i.e., number of interviews)
=
the size of the sample (i.e., number of interviews)
Using these formulas, the margin of error for a sample size of 6,001
interviews is d = 0.0167, using an average
of 1.75 and setting
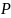 equal to 0.50. We expect the design effect for the NTSS to be similar
to the design effect for the 2016 Motor Vehicle Occupant Safety
Survey (MVOSS), which was 1.73 and 1.76 for the two versions of the
survey.19
equal to 0.50. We expect the design effect for the NTSS to be similar
to the design effect for the 2016 Motor Vehicle Occupant Safety
Survey (MVOSS), which was 1.73 and 1.76 for the two versions of the
survey.19
The total sample size for the survey is also large enough to permit
estimates for subgroup analyses including age, sex, race/ethnicity,
and other demographic characteristics. Using the formulas above, and
assuming an average
of 1.75 and setting
equal to 0.50, a subgroup that represents at least 10% of the total
sample will have a 95% confidence interval of +/- at most 5.3% for
the margin of error. Table 6 includes expected 95% error margins for
demographic groups assuming the sample size is proportional to the
population.
Table 6. Expected 95% Error Margins for Subgroups.
Demographic Group |
Population Percentage |
+/–95% CIs |
Sex |
|
|
Male |
49% |
2.4% |
Female |
51% |
2.3% |
Age Group |
|
|
18-34 |
30% |
3.1% |
35-54 |
33% |
2.9% |
55+ |
37% |
2.8% |
Race/Ethnicity |
|
|
Hispanic (any race) |
16% |
4.2% |
Non-Hispanic, White |
64% |
2.1% |
Non-Hispanic, Black |
12% |
4.8% |
Non-Hispanic, Other race |
9% |
5.6% |
The NTSS will be weighted to reduce any potential bias related to differential selection probabilities and non-response. The weighting process will compute:
Sampling weights that incorporate the probability of selection for households and the probability of selection of a respondent within a sample household;
Weight adjustments for non-response; and
Population calibration.
Sampling weights are the products of the reciprocals of the probabilities of selections associated with two sampling stages: 1) the selection of households from the ABS frame and 2) the selection of respondents within a household. The first-stage probabilities will be approximately equal since the sample is allocated proportionately to the region based on the number of addresses on the frame. The address probability of selection is multiplied by the within-household probability of selection based on the number of adults in the household as reported in the survey.
Weighting class adjustments designed to minimize the potential for non-response bias will be applied. These adjustments will be informed by the non-response analysis described in the next section. Specifically, the variables selected will be used to define weight adjustment classes (or cells) using the propensity models in that analysis. In general, adjustment classes will be homogeneous in terms of response behavior.
The weights will be calibrated based on known population totals for key demographics such as sex, age categories, education, marital status, and race/ethnicity. The calibration will be based on raking, an iterative ratio adjustment of the sample to the population based on multiple key demographic variables.
B.3. Describe methods to maximize response rates.
B.3.1 Maximizing Response
NHTSA is taking steps to boost the NTSS response rate. Foremost will be NHTSA’s use of the multi-mode approach, where different options for responding are sequentially presented to prospective respondents (web and mail). This approach offers greater opportunity for people to use a response mode that they prefer and with which they are comfortable, which should enhance participation.
The protocol includes up to five mailings to non-response households. The first contact will include a $1 pre-incentive and a $10 post-incentive upon completion. An incentive experiment done for NSPBAKB found that a $1 pre-incentive and $10 post-incentive provided the most cost-efficient way to increase response when compared to $1 pre-incentive and $5 post-incentive.
In contacting respondents, NHTSA will use white envelopes printed with NHTSA's logo according to NHTSA style guidelines to reinforce the legitimacy of the survey. People will often open envelopes with Government logos out of curiosity as to why they are being contacted by the Government. As stated in the previous section, the invitation to participate in the survey will include wording in Spanish for those who live in Census blocks where the percentage of limited English-speaking households20 is at least 15% of the total households in the block so that they are not excluded from the survey.
Additionally, the pilot study will include an experiment to determine whether varying the messaging techniques used in contact materials increases response rates. Specifically, to build trust and legitimacy, and to evoke motivation to participate, all initial invitation letters in the pilot study will include a description of NHTSA programs and their impacts. The experiment will examine the best method for providing this information: either 1) a brief statement in the body text of the initial invitation letter, along with a NHTSA URL to learn more or 2) a one-third sheet mailing insert included with the initial invitation letter that contains more in-depth information about NHTSA programs and their impacts. The results of this experiment in the pilot study will be used to inform which messaging technique will be used in the full survey administration.
In adapting the questionnaires to multi-mode administration, the project team will apply principles of heuristics that people follow in interpreting visual cues when visually laying out the questions. Another facilitator of responses will be adaptation of the web-based questionnaires for mobile platforms (e.g., smartphones, tablets) so that prospective respondents who wish to use such devices when taking the survey are not deterred. Once a questionnaire is programmed, the survey platform will automatically adapt the presentation to optimize completion on a mobile device.
The survey will include assistance devices for respondents so that they do not become frustrated and terminate their participation prior to submission of a completed questionnaire. For the web response mode, this will include easy navigation from page to page and the capability for respondents to pause and leave the system and then re-enter at the departure point without losing any previously inserted information.
During the survey administration, ICF will maintain support for the respondents via an e-mail help desk and a toll-free phone number. Clear instructions for accessing this support will be provided on paper materials and the web survey.
B.3.2 Non-response Analysis
Non-response bias will occur if there are differential response rates for certain subgroups of the sample, and these subgroups differ with respect to the substantive survey data. Differential response occurs when one subgroup responds to the survey at a higher rate than another subgroup (e.g., males vs. females). Therefore, the non-response analysis will focus on the distribution of respondents as compared to the expected distribution based on the population.
The analysis of non-response bias for the NTSS will follow two steps.
Bivariate analyses. First, the analysis will compare the distribution of survey respondents with known population distributions. This comparison will focus on key demographic variables such as race/ethnicity, sex, age groups, and education. Because many of these same factors will be used during post-stratification in the survey weighting process, the analysis will consider un-weighted data and data that are weighted prior to the post-stratification step, as well as using the final adjusted weights. Note that these analyses will capitalize on information on the frame (e.g., single/multi-family address), as well as on Census data for the geographic area where the address is located. The results of these analyses will be used to identify potential variables for inclusion in multiple logistic regression analyses (2).
Multiple logistic regression analyses. The demographic variables found to be significant in these bivariate analyses (or subgroup analyses) will then be included in multiple logistic regression models. In these logistic models, usually called propensity models, the dependent variable is a dichotomous (0-1) indicator for response, so the logistic model may be expressed in terms of the probability of a response. The variables that turn out to be significant in these propensity models will be considered for weight adjustments for non-response (i.e., will be candidates for defining weight adjustment classes). This approach will ensure that weight adjustments minimize the potential for non-response bias.
The non-response analysis will inform the weighting adjustments to correct for a sample that is disproportionate from the population. These weighting adjustments will mitigate the risk on non-response bias to the extent that the substantive survey data is correlated with the observed differences in respondents and non-respondents.
B.4. Describe any tests of procedures or methods to be undertaken.
The questions on the NTSS will be cognitively tested, and the web and paper survey instruments will be subjected to usability testing. Additionally, a methodological experiment is planned for the Pilot Study (see Section B.4.4).
B.4.1 Cognitive Testing of the Draft Survey Instrument
Cognitive testing uses in-depth interviewing to understand the mental processes respondents use to answer survey questions, evaluate questions against measurement objectives, and measure the accuracy of their response data. In the Fall of 2023, ICF will cognitively test the invitation materials and a subset of questions in the NTSS questionnaire by recruiting adult participants using free and/or paid platforms. ICF will conduct one-on-one cognitive interviews with six groups of nine participants each for a total of 54 participants. The groups are designed to test combinations of modules 1, 2, 3, and 4, as well as invitation materials, screener questions, and the core module of questions, both in English and Spanish. Interviews conducted in Spanish are necessary to ensure that the Spanish version of the survey is accurate, appropriate, and evokes the same interpretations of questions as the English version of the survey. Table 5 shows a summary of the cognitive interview testing groups. ICF will conduct the interviews remotely using screensharing and audioconference software. Each interview will last between 60 and 90 minutes, and participants will be provided with a $75 honorarium as a thank you for their participation. Cognitive interview results will be compiled in a report with recommended changes to the questionnaire.
Table 5. Cognitive Interview Testing Groups.
Group |
Module Name (Number) |
Language |
n |
1 |
Seat Belts (1), Distracted Driving (2) |
English |
9 |
2 |
Seat Belts (1), Distracted Driving (2) |
Spanish |
9 |
3 |
New and Emerging Vehicle Technologies (3), Traffic Safety and Enforcement Attitudes (4) |
English |
9 |
4 |
New and Emerging Vehicle Technologies (3), Traffic Safety and Enforcement Attitudes (4) |
Spanish |
9 |
5 |
Invitation Materials and Core Questions, Screener |
English |
9 |
6 |
Invitation materials and Core Questions, Screener |
Spanish |
9 |
B.4.2 Web-based Questionnaire Usability Testing
In the Fall of 2024, ICF will complete usability testing of both the web and paper questionnaires, with nine participants per mode (web and paper; 18 total participants). For usability testing of the web-based questionnaire, nine participants during in-person sessions will be asked to follow the instructions in the invitation letter as if they were at home, starting with going to the website and accessing the survey. Participants will then be asked to complete specific survey portions while thinking aloud. The facilitator will note errors and watch for hesitation, confusion, or frustration. Web-based questionnaire testing will include both desktop and mobile devices. Tests will be recorded to identify:
Problems with following invitation letter instructions and/or accessing the survey;
Problems with navigating screens, sections, and questions;
Confusion about where and when responses are saved and returning to the survey later; and
Interface elements (e.g., icons, menus, buttons, forms, messages, warnings, alerts).
Adjustments will be made to the web instrument based on the findings of this usability testing to correct for the above issues.
B.4.3 Paper Questionnaire Usability Testing
For usability testing of the paper questionnaire, nine participants during in-person sessions will be given a copy of the appropriate invitation/reminder letter and the paper survey packet and asked to complete survey items while thinking aloud. Tests will be recorded to identify:
Not marking answers in the correct location or answers not fitting in the space provided;
Missing or misunderstanding instructions (e.g., choosing multiple responses in a case where only one response is allowed); and
Difficulty following skip patterns or answering questions as “not applicable.”
Adjustments will be made to the paper instrument based on the findings of this usability testing to correct for the above issues.
B.4.4 Pilot Testing
The pilot test will be used to test the entire survey administration system prior to launching the full study. ICF will send 1,200 invitations and will test the core questions and all permutations of the four modules. The pilot will be administered to exactly mirror the survey data collection protocols.
The pilot phase will also test two experimental conditions, varying the messaging techniques used in survey contact materials. To build trust and legitimacy to the survey in order to increase motivation to participate, all initial survey invitation mailings will include a description of NHTSA programs and their impacts. The experiment will test the best method for providing this information about NHTSA: 1) a brief statement in the body text of the invitation letter, along with a URL to the NHTSA website to learn more or 2) a one-third sheet mailing insert included with the invitation letter containing more in-depth information about NHTSA. The sample will be equally split across both conditions such that 600 of the initial invitation letters sent to households will contain the invitation letter with the NHTSA description and URL only, and 600 initial invitation letters will also contain an insert about NHTSA programs and their impacts. ICF and NHTSA will evaluate the results of the experiment following the pilot and determine messaging technique to implement for full fielding. Specifically, we will determine whether one messaging technique yielded significantly higher response rates and, if that technique is associated with higher costs (i.e., the one-third sheet mailing insert), we will determine whether the increase in response rate is sufficiently large to offset the higher costs (e.g., of printing the insert).
B.5. Provide the name and telephone number of individuals consulted on statistical aspects of the design.
The following individuals have reviewed technical and statistical aspects of procedures that will be used to conduct the NTSS:
Christine Watson, Ph.D. NHTSA Project Manager/COR(TO) Research Psychologist 1200 New Jersey Avenue SE Washington, DC 20590 202-366-7345 Christine.Watson@dot.gov
|
Heather Driscoll ICF, Project Manager (Contractor) 530 Gaither Road, Suite 500 Rockville, MD 20850 802-264-3706 Heather.Driscoll@icf.com
Christopher Doyle ICF, Administrative Manager (Contractor) 530 Gaither Road, Suite 500 Rockville, MD 20850 802-264-3727 Christopher.Doyle@icf.com |
Kisha Bailly ICF, Quality Assurance Reviewer (Contractor) 530 Gaither Road, Suite 500 Rockville, MD 20850 612-455-7471 Kisha.Bailly@icf.com
|
Randy ZuWallack ICF, Senior Statistician (Contractor) 530 Gaither Road, Suite 500 Rockville, MD 20850 802-264-3724 Randy.Zuwallack@icf.com |
1 The Abstract must include the following information: (1) whether responding to the collection is mandatory, voluntary, or required to obtain or retain a benefit; (2) a description of the entities who must respond; (3) whether the collection is reporting (indicate if a survey), recordkeeping, and/or disclosure; (4) the frequency of the collection (e.g., bi-annual, annual, monthly, weekly, as needed); (5) a description of the information that would be reported, maintained in records, or disclosed; (6) a description of who would receive the information; (7) if the information collection involves approval by an institutional review board, include a statement to that effect; (8) the purpose of the collection; and (9) if a revision, a description of the revision and the change in burden.
2 https://www.census.gov/library/stories/2021/08/united-states-adult-population-grew-faster-than-nations-total-population-from-2010-to-2020.html
3 Link, M. W., Battaglia, M. P., Frankel, M. R., Osborn, L., & Mokdad, A. H. (2008). A comparison of address-based sampling (ABS) versus random-digit dialing (RDD) for general population surveys. Public Opinion Quarterly, 72(1), 6-27.
4 Iannacchione, V. G. (2011). The changing role of address-based sampling in survey research. Public Opinion Quarterly, 75(3), 556-575.
6 Spado, D., Schaad, A., & Block, A. (2019, December). 2016 Motor Vehicle Occupant Safety Survey; Volume 2: Seat belt report (Report No. DOT HS 812 727). National Highway Traffic Safety Administration.
7 Schroeder, P., Kostyniuk, L., & Mack, M. (2013, December). 2011 National Survey of Speeding Attitudes and Behaviors (Report No. DOT HS 811 865). National Highway Traffic Safety Administration.
8 Iannacchione, V. G., Staab, J. M., & Redden, D. T. (2003). Evaluating the use of residential mailing addresses in a metropolitan household survey. Public Opinion Quarterly, 67(2), 202-210.
9 Link, M. W., Battaglia, M. P., Frankel, M. R., Osborn, L., & Mokdad, A. H. (2008). A comparison of address-based sampling (ABS) versus random-digit dialing (RDD) for general population surveys. Public Opinion Quarterly, 72(1), 6-27.
10 Iannacchione, V. G. (2011). The changing role of address-based sampling in survey research. Public Opinion Quarterly, 75(3), 556-575.
11 American Association of Public Opinion Research (AAPOR), Task Force on Address-based Sampling. (2016) Address-based sampling. http://www.aapor.org/Education-Resources/Reports/Address-based-Sampling.aspx
12 Note that the inclusion of college dormitories in the DSF (and thus, the sample) is inconsistent and depends on how the dormitory receives mail. If students living in a dorm receive mail directly from USPS, then their addresses are included in the DSF. If a university has their own mailroom, an address within a dorm could be included in a drop point if the address receives delivery from the post office to a single address. However, in other cases, a university may have a private zip code, so the dorm (and units within the form) would not be included in the DSF.
13 Bailly, K., Martin, K. & Block, A. (2019, December). 2016 Motor vehicle occupant safety survey: Volume 1, Methodology report (Report No. DOT HS 812 851). National Highway Traffic Safety Administration. https://rosap.ntl.bts.gov/view/dot/43610
15 Battaglia, M. P., Link, M. W., Frankel, M. R., Osborn, L., & Mokdad, A. H. (2008). An evaluation of respondent selection methods for household mail survey. Public Opinion Quarterly, 72(3), 459–469.
16 Olson, K., Stange, M., & Smyth, J. (2014). Assessing within-household selection methods in household mail surveys. Public Opinion Quarterly, 78(3), 656–678.
17 Boyle, J., Tortora, R., Higgins, B., & Freedner-Maguire, N. (2017). Mode effects within the same individual between web and mail administration. AAPOR 72nd annual conference, May 18-21, 2017.
18 The U.S. Census Bureau considers this to be households where no residents aged 14 years or older speak English well.
19 Bailly, K., Martin, K. & Block, A. (2019, December). 2016 Motor vehicle occupant safety survey: Volume 1, Methodology report (Report No. DOT HS 812 851). National Highway Traffic Safety Administration. https://rosap.ntl.bts.gov/view/dot/43610
20 The U.S. Census Bureau considers this to be households where no residents aged 14 years or older speak English well.
| File Type | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
| Author | randolph.atkins |
| File Modified | 0000-00-00 |
| File Created | 2025-03-14 |
© 2026 OMB.report | Privacy Policy